「ローカルAIを業務で使いたいけれど、クラウドにデータを投げるのはセキュリティ的にNGだし、かといって高性能なAIを動かすには超高額なPCが必要でしょ?」──そんなジレンマに頭を抱えていませんか?
社外秘のデータや顧客情報を扱うビジネスの現場において、プライバシーの壁は想像以上に厚いものです。「安全に、でも最先端のAIパワーを自社のパソコンだけでサクサク動かしたい」というのは、多くの担当者にとって長年の悲願でした。
そんな中、2026年6月にGoogle DeepMindが発表した最新のオープンモデル「Gemma 4 12B Unified」が、これまでの常識をガラリと塗り替えようとしています。
このモデルの凄さは、私たちが普段仕事で使っているような「一般的なノートPC(メモリ16GB)」という限られた環境で、テキストだけでなく画像・音声・動画までをサクサク処理できる圧倒的な軽さと賢さを両立させた点にあります。
もう、莫大なクラウド利用料に怯える必要も、コンプライアンスの心配をしながら外部にデータを送る必要もありません。機密情報をガッチリ守りながら、自分専用の超優秀なAIアシスタントをデスクの上で育てる──そんな「真のオンデバイスAI(ローカルAI)」の時代が、いよいよ現実のものになったのです。
この記事では、この「Gemma 4 12B Unified」がビジネスの現場をどう変えるのか、そしてあなたの手元のPCで今すぐ最先端の知能を動かすための具体的な活用方法まで、分かりやすく徹底解説します。
簡単に説明する動画を作成しました!
目次
独自アーキテクチャが切り拓くローカルAIの新時代
Gemma 4 12Bの登場は、単なる既存モデルのアップデートではありません。
これは、AI開発におけるパラメータの多さこそが正義であるというこれまでの常識に対して、Googleが強力な再定義を行ったものなのです。
従来のローカル向けモデルは、軽量化のために推論能力や複数のデータを処理するマルチモーダル対応を削るのが通例でした。
しかし、Gemma 4 12Bは設計そのものを刷新することで、この二つの難しい課題をきれいに解消しました。
Gemma 4 12Bの基本コンセプトと家族構成
Gemma 4ファミリーは、モバイルデバイスからハイエンドワークステーションまでをカバーする広範なラインナップを展開しています。
その中で12Bは、エッジデバイス向けの機動力と、サーバー級モデルの深い思考力を併せ持つ完璧な中間点に位置づけられています。
| モデル名 | 総パラメータ数 | 層数 (Layers) | 対応モダリティ | コンテキスト窓 |
| E2B / E4B | 2.3B / 4.5B (実効) | 35 / 42 | テキスト・画像・音声 | 128K |
| 12B Unified | 11.95B | 48 | テキスト・画像・音声・動画 | 256K |
| 26B A4B (MoE) | 25.2B (Active 3.8B) | 30 | テキスト・画像・動画 | 256K |
| 31B Dense | 30.7B | 60 | テキスト・画像・動画 | 256K |
11.95Bのパラメータと48層のレイヤー構造を持つ12Bモデルは、256Kトークンという膨大なコンテキストウィンドウをサポートします。
これは数百ページのドキュメントを一括で処理できる能力を意味するものです。
これにより、いつものラップトップ上での本格的な業務効率化の実現を可能にします。
Apache 2.0ライセンスがもたらすビジネスの自由度
技術的進化と同様に重要なのが、ライセンスの変更です。
Gemma 4は完全にオープンなApache 2.0ライセンスで提供されています。
これは、企業にとってのデータ主権を確保するための経営判断を後押しするものとなります。
従来の独自ライセンスとは異なり、Apache 2.0では商用利用や独自データによるカスタマイズが完全に自由であり、法的・心理的な障壁が排除されました。
企業はGoogleの最新研究成果であるGemini 3の知見をベースとしたモデルを、自社のクローズドな資産として運用し、独占することが可能です。
これは、情報の外部流出を厳格に禁じる法務や医療、製造といったセクターにおいて、計り知れない戦略的価値をもたらします。
アーキテクチャの基本概念とライセンスの優位性を理解したところで、次は、このモデルがなぜこれほどまでに軽量かつ高速なのかが気になりますよね。
その仕組みについて、ここからは私と一緒に設計の魔法を深掘りしていきましょう。
エンコーダーレス設計:驚異の軽量化と高速化の秘密
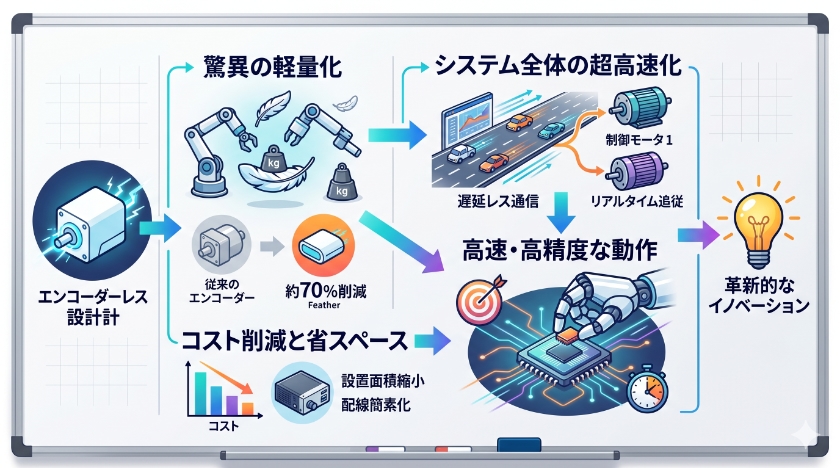
AIモデルのサイズを抑えつつ多機能を維持するための戦略として、Googleはエンコーダーレスという革新的な統一アプローチを採用しました。
外部エンコーダーを排除した統一デコーダーの戦略的意義
従来のマルチモーダルAIは、画像専用のVision Transformerや音声専用のConformerといった巨大な外部エンコーダーを本体に接続する継ぎ足し型の構造が主流でした。
しかし、これでは各エンコーダーのメモリ消費が嵩み、エンドツーエンドの学習が困難になるという課題があったのです。
Gemma 4 12Bは、これらの重い外部モジュールを排除し、単一のデコーダーに全てを統合しました。
画像処理では、550M規模のViTに代わり、わずか35Mの軽量なビジョン・エンベッダーを採用し、48×48のパッチを直接射影します。
音声処理にいたっては外部エンコーダーを通さず、16kHzの生の音声波形を40msのフレーム単位で直接射影レイヤーに送り込む仕組みです。
この設計の最大のメリットは、Unified Fine-tuning(統一的な微調整)にあります。
全てのモダリティが同一の重みを共有しているため、特定の専門分野に特化させたい場合も画像・テキストの経路を分けることなく、一度のパスでモデル全体を最適化できます。
これは開発コストを劇的に下げ、ドメイン特化型モデルの精度を最大化する戦略的アドバンテージです。
16GBメモリで実現する真のローカル実行
この効率化により、ハードウェア要件は劇的に緩和されました。
4ビット量子化(Q4_0)では重みファイルは約6.7GBとなり、16GB RAMのラップトップでOSと併用しても余裕を持って動作します。
8ビット量子化(SFP8)でも約13.4GBであり、より高い精度を求めるプロフェッショナルな用途にも対応可能です。
ただし、超DX仕事術の視点から実務上のリスクヘッジとして注意すべきは、KVキャッシュの問題です。
256Kのフルコンテキストを使用する場合、計算過程の一時データがメモリを圧迫し、16GBでは不足する可能性があります。
長大なドキュメント解析を行う際は、コンテキストを32K程度に制限するか、32GB以上のメモリを搭載したワークステーションへの移行を推奨します。
効率的な設計が、実際のベンチマーク結果としてどのような数字に化けるのか。
次はその旧世代モデルを凌駕する衝撃的な事実を確認しましょう。
パフォーマンス分析:2倍のサイズを融通する実力
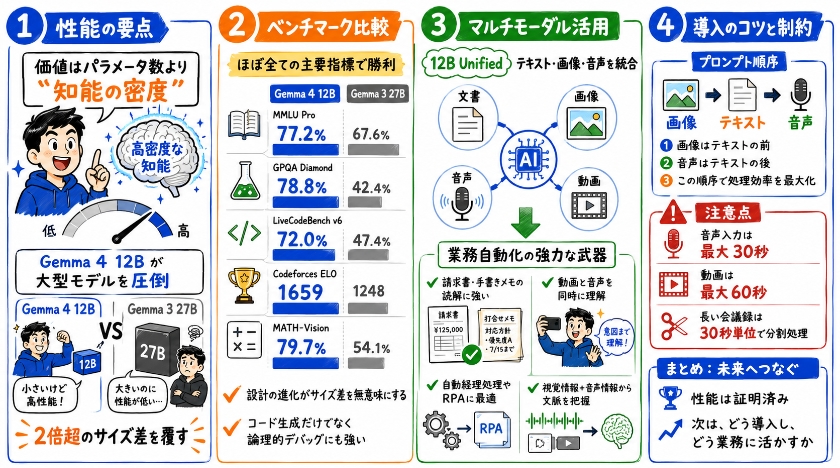
AIモデルの価値は、パラメータ数という体格ではなく、知能の密度で決まります。
Gemma 4 12Bは、前世代の大型モデルを完全に圧倒する知能指数を示しているのです。
旧世代の大型モデルを圧倒するベンチマーク結果
Gemma 4 12Bは、サイズが2倍以上あるGemma 3 27Bに対し、ほぼ全ての主要指標で明確な勝利を収めています。
- MMLU Pro (総合知識): 77.2%(Gemma 3 27B:67.6%)
- GPQA Diamond (科学的推論): 78.8%(Gemma 3 27B:42.4%)
- LiveCodeBench v6 (コーディング): 72.0%
- Codeforces ELO (競技プログラミング): 1659
- MATH-Vision (画像ベースの数学): 79.7%
この数値が示すのは、モデル設計の進化がいかにサイズ差を無意味にするかという事実です。
特にLiveCodeBenchやCodeforcesのスコアは、この12Bモデルがコードを生成するだけでなく、論理的にデバッグできる能力を備えていることを裏付けています。
テキスト・画像・音声を統合するマルチモーダル機能
12B Unifiedは、みなさんのビジネスプロセスを自動化する強力な武器となります。
ドキュメント解析(OmniDocBench 1.5)における請求書や手書きメモの読解精度は上位モデルに肉薄しており、自動経理処理などのRPAに最適です 。
動画・音声の同時理解について、5分間の動画を1FPSで解析したデモでは、視覚情報と音声情報を統合し、男性が自撮りをしている意図といった文脈まで正確に把握しました。
ここで、超DX仕事術の視点からプロンプトエンジニアリングにおける最適なコツをお伝えしましょう。
Googleは、画像はテキストの前、音声はテキストの後に配置することを推奨しています。
この順序を守ることで、統一デコーダーの処理効率が最大化されます。
一方で、仕様上の制約として注意すべきは、ネイティブ音声入力は最大30秒、動画は最大60秒という物理的な制限がある点です。
長時間の会議録を直接読み込ませる場合は、システム側で30秒単位の断片に分割して処理する仕組み作りが必要となります。
性能が証明された今、次はこの強力なツールを具体的にどう導入し、未来のビジネスに活かすべきかを考えましょう。
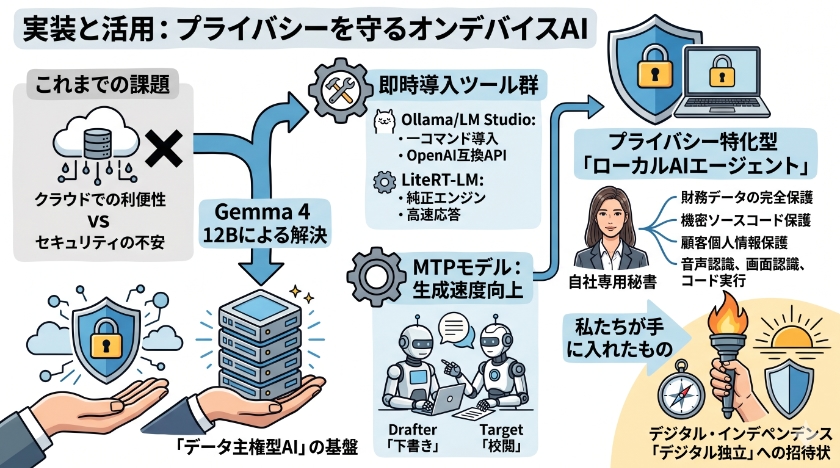
実装と活用:プライバシーを守るオンデバイスAIの未来
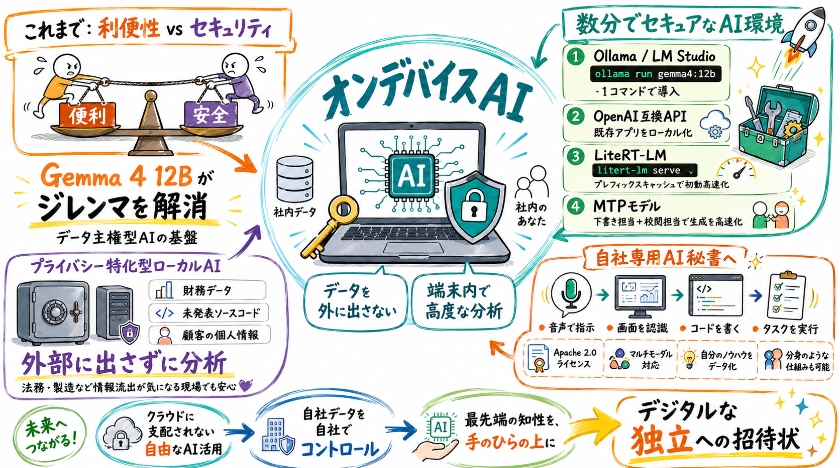
これまでのAI活用は、常に利便性とセキュリティのトレードオフに悩まされてきました。
しかし、Gemma 4 12Bは、そのジレンマを解消するデータ主権型AIの基盤となります。
即時導入を支える強力なエコシステム
開発者や意思決定者は、ツールを用いることで、わずか数分でセキュアなAI環境を構築できます。
OllamaやLM Studioを使えば、ollama run gemma4:12bの一コマンドで導入が完了します。
OpenAI互換APIとして機能するため、既存のアプリケーションを即座にローカル化できます。
また、Google純正の推論エンジンであるLiteRT-LMでlitert-lm serveを使用すれば、ステートレスなプレフィックスキャッシュを有効にし、初動の応答を劇的に高速化できます。
さらに、下書き担当が先行して予測し、校閲担当が検証する仕組みのMTPモデルにより、生成速度をさらに向上させます。
私がコンサルタントとして多くのツールを見てきた経験から言っても、このような自動化と高速化の仕組みは業務効率化に直結する重要な要素です。
プライバシー特化型ローカルAIエージェントへの応用
Gemma 4 12Bを採用することは、単なるコスト削減ではなく、未来を守るための戦略的投資です。
財務データ、未発表のソースコード、顧客の個人情報を一切外部に出さず、端末内で高度な分析を実行できます。
情報流出が気になる法務や製造などの現場でも、これなら安心して使えますよね。
Apache 2.0ライセンスとマルチモーダル対応を活かし、音声で指示を出し、画面を認識し、コードを書いてタスクを実行する自社専用秘書の開発が可能です。
この技術を使えば、自分しか持っていないノウハウをデータ化して自分の分身を作るような仕組み作りも夢ではありません。
Gemma 4 12Bは、単なるソフトウェアではなく、私たちのコンピューティング環境を再定義する手のひらの上の知能です。
クラウドに支配されない自由なAI活用が、今ここから始まります。
超DX仕事術の視点から見ても、私たちが手に入れたのは単なる新技術ではありません。
それは、自社のデータを自社でコントロールしつつ、最先端の知性を享受するデジタルな独立への招待状なのです。
DXやITの課題解決をサポートします! 以下の無料相談フォームから、疑問や課題をお聞かせください。40万点以上のITツールから、貴社にピッタリの解決策を見つけ出します。
このブログが少しでも御社の改善につながれば幸いです。
もしお役に立ちそうでしたら下のボタンをクリックしていただけると、 とても嬉しく今後の活力源となります。 今後とも応援よろしくお願いいたします!
IT・通信業ランキング | にほんブログ村 |
もしよろしければ、メルマガ登録していただければ幸いです。
【メルマガ登録特典】DX戦略で10年以上勝ち続ける実践バイブル『デジタル競争勝者の法則』をプレゼント!
 今すぐプレゼントを受け取る
今すぐプレゼントを受け取る