「社内の機密データを安全に扱うためにローカルLLMを導入したいけれど、専門用語が多くて何から始めればいいか分からない…」──そんな悩みを抱えていませんか?
最近では高性能なオープンモデルが次々と登場していますが、「自分のPC環境で本当に動くのか」「どのGPUを選べばいいのか」と、ハードルの高さを感じて導入をためらっている方は多いはずです。ネット上には断片的な情報が溢れており、いざ試そうとしても環境構築の段階でエラーが出て挫折してしまうケースも珍しくありません。
実は、ローカルLLMをスムーズに実務へ定着させられるかどうかの最大の分かれ目は、「自社の目的に合ったモデル選びと、それに最適化されたPC環境の構築」にあります。
単にハイスペックな機材を揃えれば良いというわけではなく、用途に応じた適切なモデルとリソースのバランスを見極めることが重要です。ここさえクリアできれば、情報漏洩のリスクを一切気にすることなく、独自のデータを安全かつ自由に活用できる強力なAI環境を手に入れることができます。
この記事では、2026年の最新事情を踏まえ、ローカルLLMの具体的な導入手順から人気モデルの比較、そして気になるPC環境やGPUスペックの要件までを網羅的に解説します。迷うことなく最適な環境を構築し、ローカルLLMを業務の武器にするための第一歩を踏み出しましょう。
簡単に説明する動画を作成しました!
目次
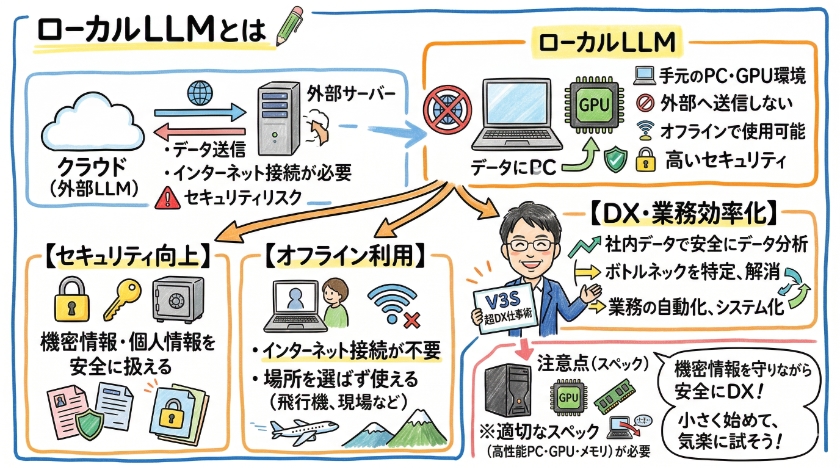
ローカルLLMとは
超DX仕事術の中でも、データ活用と自動化を実現するためにAIの存在はますます大きくなっています。最近、クライアントからよく相談を受けるのが、このローカルLLMについてです。
定義と特徴
ローカルLLMとは、クラウドサーバーを介さずに、個人のPCやGPU環境で動作する大規模言語モデルのことです。
外部へのデータ送信が不要なため、セキュリティが重要な場合に特に有用です。
また、インターネット接続が不要なため、オフライン環境でもAIの利用が可能です。
以前、機密性の高い顧客データを扱う企業でDX化を支援した際、クラウドのツールでは情報漏洩のリスクがあり導入を見送った経験がありました。しかし、ローカルLLMであればその課題をクリアできるのです。
モデルのサイズやパラメータ数に応じて必要なスペックは異なりますが、適切な環境を選択することで、快適な推論処理が実行できます。
大規模言語モデルとの違い
大規模言語モデルは通常、クラウド上で動作し、APIを通じて利用します。
一方、ローカルLLMは、PCにダウンロードして実行するため、外部サーバーへの依存がありません。
これにより、データプライバシーが向上し、インターネット接続がない環境でも利用可能になります。
これは、超DX仕事術で提唱しているV3Sのフレームワークを使って業務のボトルネックを特定する際にも、社内のローカル環境で安全にデータを分析できるという大きな強みに繋がります。
ただし、ローカルLLMの導入には、高性能なGPUや十分なメモリが必要となる場合が多く、PCのスペックが重要になります。
日本語対応の重要性
ローカルLLMを導入する上で、日本語対応は非常に重要な点です。
海外製のITツールを選定する際、英語のサポートで苦労した私の経験をお話ししましたが、AIモデルにおいても全く同じことが言えます。
業務で日本語のテキストデータを処理する場合、モデルが日本語に適切に対応しているかを確認する必要があります。
日本語の学習データ量や、日本語の生成能力が高いモデルを選択することで、より実用的な活用が可能になります。
また、日本語対応のモデルは、日本語の自然言語処理タスクにおいて、より高い性能を発揮することが期待されます。
ぜひ、ご自身の業務環境と照らし合わせながら、気楽に最適なツールの導入を検討してみてください。
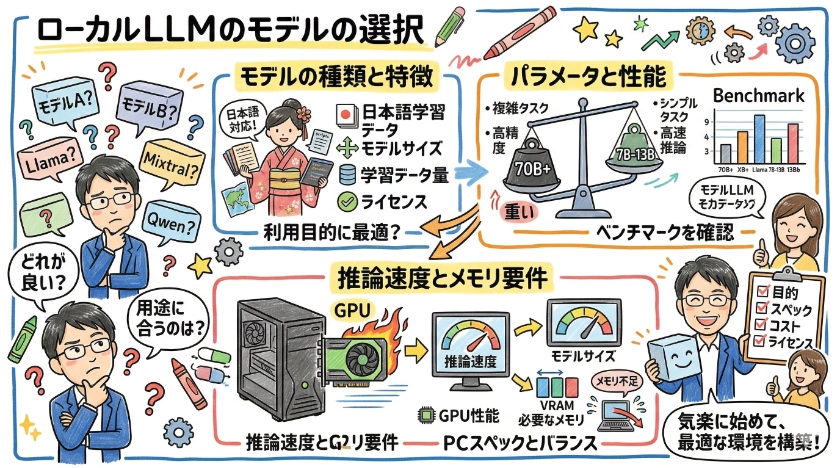
ローカルLLMのモデルの選択
モデルの種類と特徴
ローカルLLMを導入する際、まず重要なのがモデルの選択です。
多様なモデルが存在し、それぞれ特徴が異なります。
モデルのサイズ、パラメータ数、学習データ、対応言語などを比較検討し、利用目的に最適なモデルを選びましょう。
超DX仕事術でもお伝えしているように、まずは小さく始めて気楽に試し、自分に合うか判断することが大切です。
特に、日本語対応のモデルは、日本語のテキストデータを扱う業務において必須です。
オープンソースのモデルも多く、無料で利用できるものもありますが、ライセンスや利用規約を確認することが重要です。
モデルによっては、特定のGPU環境での動作に最適化されている場合もありますので、PCのスペックと合わせて検討しましょう。
パラメータと性能の比較
ローカルLLMの性能を比較する上で、パラメータ数は重要な指標の一つです。
一般的に、パラメータ数が多いほどモデルの表現力が高く、複雑なタスクに対応できます。
しかし、パラメータ数が多いほど、必要なメモリ量や推論時間が長くなるため、PCのスペックとのバランスを考慮する必要があります。
これは、動画編集の際にスペックの低いパソコンを使うと能力以上のムリな負荷がかかり、作業が止まってしまうと説明したのと同じ理屈ですね。
また、同じパラメータ数でも、学習データやモデルのアーキテクチャによって性能が異なるため、実際にベンチマークテストの結果などを確認し、比較検討することが重要です。
高性能なGPUを利用することで、より高速な推論が可能になります。
推論速度とメモリ要件
ローカルLLMの導入において、推論速度とメモリ要件は重要な検討事項です。
モデルのサイズに応じて必要なメモリ容量が異なり、十分なメモリがない場合、動作が遅くなる可能性があります。
また、GPUの性能も推論速度に大きく影響します。
ここでV3Sのフレームワークを使って現在の業務のボトルネックを可視化し、本当にそこまでの推論速度が必要かを見極めるのも一つの手です。
高性能なGPUを使用することで、推論速度を向上させることができますが、コストも増加します。
業務でローカルLLMを活用する場合、必要な推論速度とメモリ要件を考慮し、PC環境を適切に設定する必要があります。
軽量なモデルを選択することで、メモリ要件を抑えつつ、ある程度の推論速度を確保することも可能です。
GPUのスペックを確認し、最適な環境を構築しましょう。
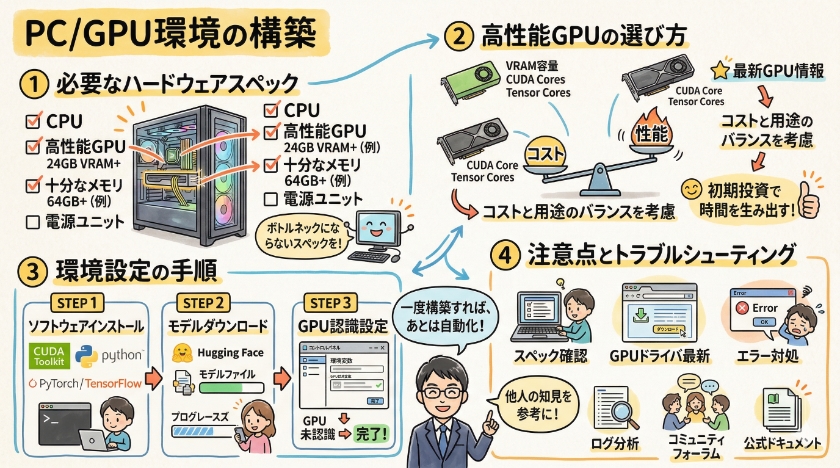
C/GPU環境の構築
必要なハードウェアスペック
ローカルLLMを導入し、快適に動作させるためには、適切なハードウェアスペックが不可欠です。
特に重要なのは、GPUの性能とメモリ容量です。
大規模言語モデルは、大量のデータとパラメータを処理するため、高性能なGPUが不可欠であり、それにより高速な推論が可能になります。
PCのスペックが低いと、推論速度が遅くなり、実用的な活用が難しくなる場合があるため、導入するローカルLLMのモデルサイズに応じたスペックを準備しましょう。
超DX仕事術でお伝えしたV3Sのフレームワークを使って現状の課題を可視化しても、ハードウェアの能力が追いつかずに能力以上の負荷がかかるムリな状態が発生してしまっては元も子もありません。
また、十分なメモリがない場合、動作が不安定になる可能性もあるため、注意が必要です。
高性能GPUの選び方
高性能GPUを選択する際には、メモリ容量、CUDAコア数、Tensorコア数などを比較検討することが重要です。
ローカルLLMの推論処理はGPUに大きく依存するため、GPUの性能が直接的に推論速度に影響します。
特に、大規模言語モデルを扱う場合は、より高性能なGPUが求められます。
コストを考慮しながら、利用目的に最適なGPUを選択することが重要です。
私も過去に動画のエンコードの時間を削減するため、高いスペックのMacBook Proを購入した経験をお話ししましたが、初期投資を行うことで結果的にボトルネックが解消され、かなりの時間を生み出すことができました。
GPUの選択によっては、ローカルLLMの活用範囲が広がり、より高度な処理が可能になります。
最新のGPU情報を確認し、最適なモデルを選択しましょう。
環境設定の手順
ローカルLLMを動作させるための環境設定は、いくつかの手順に分かれます。
まず、必要なソフトウェア(CUDA Toolkit、Pythonなど)をインストールします。
次に、ローカルLLMのモデルと必要なライブラリをダウンロードします。
環境変数を設定し、GPUが正しく認識されるように設定します。
最後に、簡単なスクリプトを実行して、ローカルLLMが正常に動作するか確認します。
このような設定作業を面倒に感じるかもしれませんが、一度環境を構築してしまえば、あとはデータ流用やシステム化によって事務作業などの手作業を大幅にカットできます。
環境設定が完了すれば、ローカルLLMを活用した様々なタスクを実行できるようになります。
設定によっては、GPUドライバのバージョンが重要になる場合もあるため、注意が必要です。
ローカルLLMの導入方法
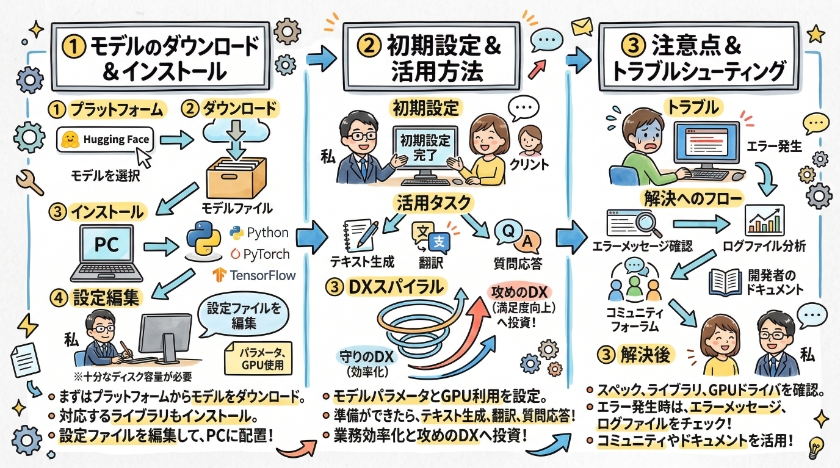
ダウンロードとインストール
ローカルLLMのモデルをダウンロードし、インストールする手順は、モデルの種類や開発環境によって異なります。
多くの場合、Hugging Faceなどのプラットフォームからモデルをダウンロードし、Pythonのライブラリを使用してインストールします。
必要なライブラリは、PyTorchやTensorFlowなど、モデルが対応しているフレームワークによって異なります。
超DX仕事術の原則でもお伝えしたように、新しいことを始める前から失敗を恐れる必要はありません。
ダウンロードしたモデルをPCに配置し、設定ファイルを編集して、ローカルLLMが正常に動作するように設定します。
インストール時には、十分なディスク容量が必要となるため、注意が必要です。
初期設定と活用方法
ローカルLLMの初期設定では、モデルのパラメータを設定し、GPUを利用するように設定する必要があります。
設定ファイルやコマンドライン引数を通じて、様々なパラメータを調整できます。
初期設定が完了したら、ローカルLLMを活用して、テキスト生成、翻訳、質問応答などのタスクを実行できます。
ローカルLLMの活用方法は多岐にわたり、業務効率化や新しいサービスの開発に貢献できます。
これはまさに、自分の業務を効率化して時間を捻出する守りのDX仕事術から、対象者の満足度を上げる攻めのDX仕事術へ投資するという、DX仕事術スパイラルを回すための強力な武器になります。
大規模言語モデルを活用することで、より高度なAI処理が可能になります。
ローカルLLMは、様々な用途に活用できるため、その可能性は無限大です。
注意点とトラブルシューティング
ローカルLLMの導入時には、いくつかの注意点があります。
まず、PCのスペックがモデルの要件を満たしているか確認する必要があります。
次に、必要なソフトウェアやライブラリが正しくインストールされているか確認します。
また、GPUドライバのバージョンが最新であることも重要です。
トラブルが発生した場合は、エラーメッセージをよく確認し、ログファイルを分析することで原因を特定できます。
それでも解決しない場合は、コミュニティフォーラムや開発者のドキュメントを参照すると良いでしょう。
超DX仕事術でも触れましたが、DX難民にならないためには、全部自分で抱え込まずに他人の成功事例や知見を参考にすることが一番の近道です。
多くのケースで、これらの情報源から解決策が見つかります。
ローカルLLMのメリットと活用法
業務への応用例
ローカルLLMの導入は、多岐にわたる業務に応用可能です。
例えば、顧客対応の自動化では、FAQ応答や問い合わせ対応をローカルLLMで効率化できます。
以前、私がクライアントのウェブサイトにチャットボットを導入して問い合わせ対応を効率化した事例をお話ししましたが、ローカルLLMを使えば機密性の高い内容でも安全に自動化できるというわけです。
社内文書の要約や翻訳にも活用でき、情報共有をスムーズに行うことができます。
また、営業資料の作成やマーケティングコンテンツの生成も、ローカルLLMの得意とするところです。
これらの業務において、ローカルLLMはデータのセキュリティを保ちつつ、迅速かつ正確な処理を実現します。
高性能なGPU環境を構築することで、より複雑なタスクも実行可能です。
導入には適切なモデルの選択が重要です。
コスト削減の可能性
ローカルLLMの導入は、長期的に見て大幅なコスト削減につながる可能性があります。
クラウドベースのAPI利用と比較して、従量課金が発生しないため、大規模なデータ処理を行う場合には特にメリットが大きいです。
また、インターネット接続が不要なため、通信コストも削減できます。
初期導入コストはかかるものの、運用コストを抑えることができるため、ROI(投資対効果)を高めることができます。
超DX仕事術では、予算を極力かけずに小さく始めることを推奨していますが、継続的に発生するランニングコストを抑えられる点は、個人やチームにとって非常に大きなアドバンテージになります。
ローカルLLMのモデルやPCのスペックに応じて必要なコストは異なりますが、適切な選択を行うことで、コストパフォーマンスを最大化できます。
大規模言語モデルの利用は、ビジネスにおける競争力を高める鍵となります。
学習と開発の促進
ローカルLLMを活用することで、AI技術の学習と開発が促進されます。
エンジニアや研究者は、ローカル環境で自由にモデルをカスタマイズし、実験的な開発を行うことができます。
失敗を恐れずにテストの一環として気楽にチャレンジできる環境は、まさにOODAループを素早く回して継続的な改善を続けるための理想的な土台です。
また、オープンソースのモデルを利用することで、無料でAI技術を学ぶことができます。
ローカルLLMは、大規模言語モデルの内部構造を理解するための貴重なツールとなり、AI技術の発展に貢献します。
GPU環境を整備することで、より高度な学習や開発が可能になります。
ローカルLLMの導入は、企業全体のAIリテラシー向上にもつながります。
V3Sのフレームワークで業務を可視化し、データ分析やモデルの改善を繰り返すことで、より実用的なAIシステムを開発できます。
まとめと今後の展望
2026年の最新情報
2026年には、ローカルLLMを取り巻く環境は大きく変化しているでしょう。
より高性能なGPUが登場し、PCのスペックも向上することで、これまで以上に大規模なモデルがローカルで動作するようになることが予想されます。
また、日本語対応のモデルもさらに進化し、より自然で流暢なテキスト生成が可能になるでしょう。
オープンソースのコミュニティも活発になり、最新の情報や技術が共有されることで、ローカルLLMの活用範囲はさらに広がることが期待されます。
記事では、最新のトレンドや技術動向を追い、皆様に有益な情報を提供していきます。
私自身、コンサルタントとして常に最新技術のアンテナを張っていますが、OODAループを意識して新しい情報を取り入れ続けることが、これからの時代を生き抜く鍵となります。
ローカルLLMの未来
ローカルLLMの未来は、非常に明るいと言えます。
AI技術の進化に伴い、ローカルLLMはますます高性能化し、様々な分野で活用されるようになるでしょう。
例えば、医療分野では、患者のデータを安全に管理しながら、診断支援や治療計画の立案に役立つ可能性があります。
私が富士通時代に携わった医療機関向けシステム開発でも痛感しましたが、医療界のデータ共有やセキュリティ管理は非常に重要であり、ローカルLLMの親和性は抜群だと感じます。
教育分野では、個別の学習ニーズに合わせた教材の生成や、学習進捗のモニタリングに活用できます。
これらの活用事例は、ローカルLLMがもたらす可能性のほんの一部です。
大規模言語モデルの進化は、私たちの生活をより豊かにするでしょう。
注目すべきポイント
ローカルLLMの導入を検討する際には、いくつかの注目すべきポイントがあります。
まず、モデルの選択です。
利用目的に最適なモデルを選び、必要なスペックを確認することが重要です。
次に、PC環境の構築です。
GPUの性能やメモリ容量を考慮し、快適な動作環境を整える必要があります。
また、セキュリティ対策も重要です。
ローカルLLMは、外部へのデータ送信が不要なため、セキュリティ面で優れていますが、不正アクセスやデータ漏洩のリスクを考慮し、適切な対策を講じる必要があります。
超DX仕事術でも触れましたが、セキュリティ事故の7割は人的要因です。
便利なITツールを使うからこそ、常にリスクを認識し、自身のセキュリティリテラシーを向上させることが不可欠です。
これらの点に注意することで、ローカルLLMを安全かつ効果的に活用できます。
大規模言語モデルを使いこなすためには、これらのポイントをしっかりと押さえておくことが大切です。
ローカルLLM 導入・比較ガイド【2026年版】に関する「よくある質問」
Q1: ローカルLLMとはそもそも何ですか?ChatGPTなどのクラウド型AIと何が違うのでしょうか?
ローカルLLMとは、インターネット上のサービスにアクセスするのではなく、自社のパソコンや社内サーバーに直接インストールして動かすAIモデルのことです。
ChatGPTのようなクラウド型AIは、入力した情報が一度外部のサーバーに送信されて処理されます。
一方、ローカルLLMは自社環境の中で処理が完結するため、データが外部に一切出ないという決定的な違いがあります。これにより、機密情報などを扱う業務でも情報漏洩のリスクを極めて低く抑えた安全な運用が可能になります。
Q2: 2026年現在、多くの企業がローカルLLMを導入している最大のメリットは何ですか?
最大のメリットは、圧倒的なセキュリティ環境下で、核心的な業務のDX化を進められることです。
社外秘のプロジェクト企画、顧客の個人情報を含むデータ分析、未公開の財務データ処理など、これまで「セキュリティの観点でクラウドAIには任せられなかった業務」をAIに代行させることができます。
また、クラウド型のようにAPIの利用量に応じた従量課金が発生しないため、利用頻度が高い企業ほど長期的なランニングコストを大幅に削減できる点も、導入を後押しする大きな要因となっています。
Q3: 自社に合ったローカルLLMを選ぶ際、どのようなポイントで比較すればよいですか?
初めての導入では、**「日本語の処理能力」「必要なマシンスペック」「商用利用の可否」**の3点を基準に比較してください。
2026年現在、日本語に特化した高性能なオープンソースモデルが多数公開されています。しかし、いくら賢いモデルでも自社のパソコンの性能をオーバーしては動かせません。
そのため、自社のハードウェア環境(特にGPUメモリ容量)で快適に動くサイズを選ぶことが重要です。また、モデルによっては自社のビジネスに活用(商用利用)して良いかどうかのライセンス条項が異なるため、必ず確認するようにしましょう。
Q4: ローカルLLMを導入するには、どれくらいのPCスペックや費用が必要ですか?
AIをスムーズに動かすためには、パソコンの頭脳であるCPU以上に「GPU(グラフィックボード)」の性能が重要になります。
日常業務のサポートレベル(小〜中規模モデル)であれば、VRAM(ビデオメモリ)が16GB〜24GB程度搭載された、数十万円クラスのAI用パソコンで十分に動作します。
社内全体で大規模に活用するシステムを構築する場合は、数百万円以上の専用サーバーが必要になることもあります。2026年はAIモデルの軽量化技術が非常に進歩しているため、まずは手の届く予算内のPCと小規模なモデルで「スモールスタート」を切るのが鉄則です。
Q5: 導入プロジェクトに失敗しないための注意点や、スムーズに進めるコツを教えてください。
DXコンサルタントとしてよく見る失敗パターンは、「とりあえず高性能なAIを導入したが、現場が使いこなせず放置される」というケースです。
これを防ぐには、「AIにどの業務を任せるのか(目的)」を導入前に明確にすることが最も重要です。議事録の要約、社内マニュアルの検索、プログラムコードのチェックなど、目的によって最適なLLMの選び方や設定が変わります。
全社で一斉に導入するのではなく、まずは特定の部署や業務に絞ってテスト運用(PoC)を行い、現場の課題を解決できているか確認しながら規模を拡大していくことが、成功への最短ルートです。
DXやITの課題解決をサポートします! 以下の無料相談フォームから、疑問や課題をお聞かせください。40万点以上のITツールから、貴社にピッタリの解決策を見つけ出します。
このブログが少しでも御社の改善につながれば幸いです。
もしお役に立ちそうでしたら下のボタンをクリックしていただけると、 とても嬉しく今後の活力源となります。 今後とも応援よろしくお願いいたします!
IT・通信業ランキング | にほんブログ村 |
もしよろしければ、メルマガ登録していただければ幸いです。
【メルマガ登録特典】DX戦略で10年以上勝ち続ける実践バイブル『デジタル競争勝者の法則』をプレゼント!
 今すぐプレゼントを受け取る
今すぐプレゼントを受け取る