「ChatGPTなどの生成AIを業務に活かしたいけれど、情報漏洩が怖くて踏み切れない…」─そんなジレンマを抱えて、導入を足踏みしている方は多いのではないでしょうか。
文書作成やデータ分析など、大規模言語モデル(LLM)の可能性は理解していても、一般的なクラウド型のサービスでは、社外秘のデータや顧客情報を入力することにどうしても抵抗が生まれます。「万が一、機密情報が外部のサーバーに流出したら…」という不安から、社内での活用が制限されてしまうケースも珍しくありません。
実際、企業が生成AIを本格的に業務へ組み込む上で最大のネックとなっているのが、この「クラウド利用に伴うセキュリティリスクとネットワークへの依存」です。
いくらAIの性能が優れていても、自社の貴重なデータを安心して預けられない環境では、真の業務改革は不可能です。しかし近年、この課題を根本から解決し、安全に社内データを活用し始めている企業があります。その切り札となるのが、外部のネットワークに依存せず、自社専用の環境でAIを動かす「ローカルLLM」です。
この記事では、機密情報の流出リスクを排除し、強固なセキュリティと高度な社内データ活用を両立させる「ローカルLLM」の具体的な導入手順から環境構築のノウハウまで、担当者必見の情報を詳しくお伝えします。
簡単に説明する動画を作成しました!
目次
ローカルLLMの導入
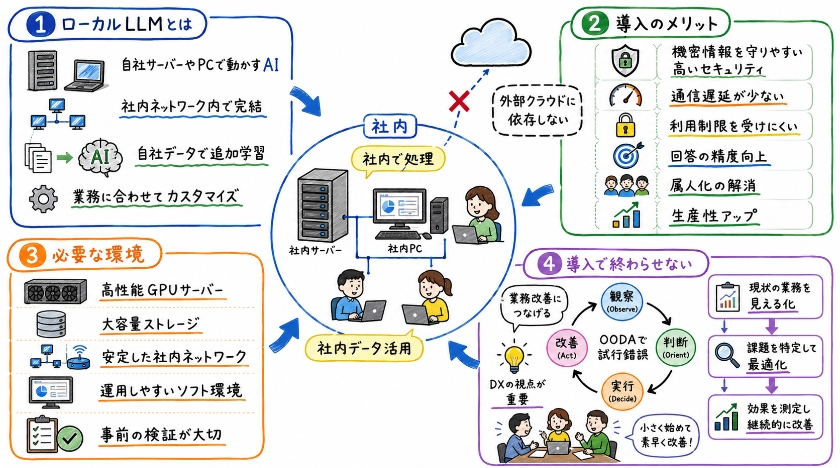
ローカルLLMとは
ローカルLLMとは、企業が自社のサーバーやPC環境内にLLMモデルを構築・運用する形態を指します。 これにより、外部のクラウドサービスに依存することなく、社内ネットワーク内でLLMの処理を完結させることが可能になります。 特に、機密性の高い社内データを扱う場合や、特定の業務要件に合わせたモデルのカスタマイズが必要な場合に、このローカルでの導入が非常に有効となります。 オープンソースのモデルをベースに、自社のデータで追加学習を行うことで、汎用モデルでは実現できないような、より専門的で精度の高い応答を生成できるようになります。
私自身、過去に多くのITツールを導入・支援してきましたが、ツールの導入自体が目的になってしまうケースを数多く見てきました。 このローカルLLMにおいても、ただシステムを構築して満足するのではなく、データに基づいて継続的に業務のやり方を変革させていくというDXの視点が不可欠です。 戦況が目まぐるしく変わる現代のビジネス環境においては、じっくり計画を立てるよりも、まずは状況を観察して臨機応変に試行錯誤を繰り返すOODAループの思考法が、ローカルLLMの運用にも求められているのです。
導入のメリット
ローカルLLMの導入は、企業にとって多大なメリットをもたらします。 まず、最も重要な点として、セキュリティの飛躍的な向上が挙げられます。 社内ネットワーク内でデータ処理が完結するため、機密情報が外部に流出するリスクを最小限に抑えることができます。 また、外部APIの利用に伴う通信遅延や利用制限も解消され、安定した速度でLLMを利用することが可能です。
さらに、独自のデータを用いたモデルの調整や、RAGのような技術を組み合わせることで、自社の業務に特化した、より高品質で正確性の高い情報生成を実現し、業務効率の向上に大きく貢献します。 これは個人の仕事を誰でも引き継げるようにして大躍進を遂げた、酒蔵の旭酒造の事例とも本質は同じです。 属人化されていた長年の経験や勘をデータ化して誰もが引き出せる仕組みを作ることは、組織全体の生産性を革命レベルにまで引き上げる原動力となります。
必要な環境の整備
ローカルLLMをスムーズに運用するためには、適切な環境の整備が不可欠です。 まず、LLMモデルの動作には高性能なGPUが搭載されたサーバーが必須となります。 モデルの規模や同時に処理するリクエスト数に応じて、必要なGPUスペックは大きく変動するため、導入前に十分な検証が必要です。 また、モデルや学習データを格納するための大容量ストレージ、そして安定した社内ネットワーク環境も重要な要素です。
動画編集の現場などでも、低いスペックのパソコンではエンコードに多大な時間がかかり作業が止まってしまいますが、最新の高性能な機材に変えるだけで、驚くほど劇的に時間が短縮されるものです。 これらの物理的なインフラに加え、モデルのデプロイや運用を効率的に行うためのソフトウェア環境の構築も検討する必要があります。 まずは現状の業務フローを見える化し、細分化し、どこに課題があるのかを特定した上で最適なシステムを組み込むV3Sのサイクルを意識してみましょう。 適切な環境構築は、ローカルLLMの実用性と性能を最大限に引き出すための鍵となります。
データの収集と整理
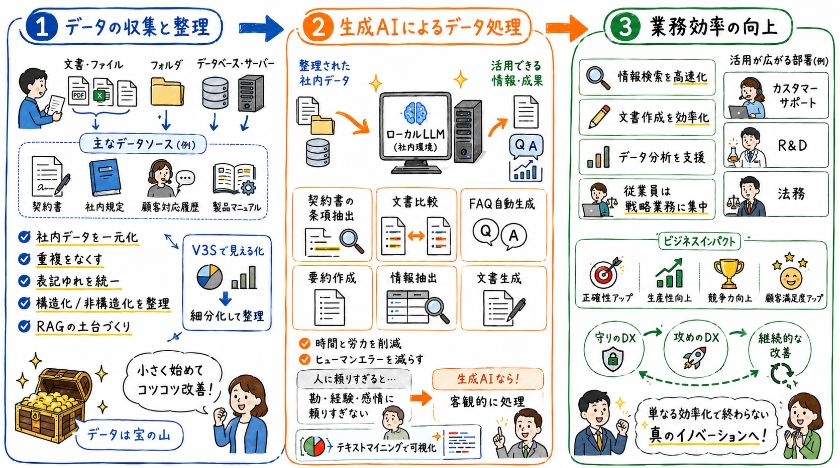
ローカルLLMを社内データ活用に効果的に利用するためには、まず対象となる社内データの収集と整理が極めて重要です。
契約書、社内規定、顧客対応履歴、製品マニュアルなど、様々な形式の文書データを一元的に集約し、アクセス可能な環境に配置します。
この際、データの重複や表記ゆれを解消し、構造化されたデータと非構造化データを適切に分類・整理することで、後続の処理におけるローカルLLMの精度と処理効率を大幅に向上させることが可能です。
特に、RAGのような技術を活用する際には、高品質で整理されたデータソースがモデルの性能を左右するため、この初期段階でのデータ整理は非常に重要な工程となります。
かつてTSUTAYAがTカードを通じて膨大な顧客の購買データを集めて戦略を立てていたように、データはまさに宝の山です 。 「超DX仕事術」でもお伝えしている通り、データを活用するためにはデータを参照する必要があり、そのためにはまずデータを正しく入力し、蓄積しなければ始まりません 。 ただ手当たり次第に集めるのではなく、まずは現状の業務フローをV3Sのフレームワークに当てはめて見える化(Visualization)し、細分化(Segmentalized)して整理していくことが大切です 。 最初から完璧なデータベースという巨大な雪だるまを作ろうとせず、小さなデータ整理の成功体験をコツコツと積み重ねていくS×3sマインドで取り組んでいきましょう 。
生成AIによるデータ処理
収集・整理された社内データは、ローカルLLMによって多岐にわたる処理が可能です。
例えば、大量の契約書から特定の条項を抽出し、比較検討する作業や、過去の顧客対応履歴を分析してFAQを自動生成するといった業務に利用できます。
また、非構造化された文書データから重要な情報を抽出し、要約を作成したり、特定の目的に応じた文書を生成することも可能です。
この処理過程では、生成AIの技術を活用し、人力では時間と労力がかかる作業を自動化することで、業務効率の向上とヒューマンエラーの削減を実現します。
私自身の経験を振り返っても、人間の記憶や判断という3K(勘・経験・感情)に頼った仕事のやり方はブレが多く、どうしても入力ミスや見落としなどの人的エラーを誘発してしまいます 。 情報漏洩や誤操作といったトラブルの7割はこうした人的要因から発生しているというデータもあります 。 文字列から有益な情報を抽出するテキストマイニングのように、膨大なテキストデータを機械的に客観的な数値やグラフへと可視化させる技術は、こうしたミスを未然に防ぐ強力な盾となります 。 機械には感情がないため、人間の本能に左右されることなく、常に冷静かつ正確にデータを処理してくれる安心感があるのです 。
業務効率の向上
ローカルLLMの導入と社内データ活用は、企業全体の業務効率の向上に大きく貢献します。
文書作成、情報検索、データ分析など、日々の業務で発生する様々なタスクを自動化または支援することで、従業員はより戦略的で創造的な業務に注力できるようになります。
特に、カスタマーサポートにおける迅速な情報提供や、R&Dにおける過去の研究データの分析、法務における契約書レビューなど、多岐にわたる部署でその効果を発揮します。
また、自社のデータで調整されたモデルは、汎用のクラウドサービスと比較して、より正確性の高い情報生成を実現し、結果として企業全体の生産性と競争力の向上に繋がります。
誰でもできるような簡単な定型作業や、やりがいの感じられない単純な事務作業に大切な時間を奪われるのは本当にもったいないことです 。 そうしたデスクトップ上の人間にしかできなかった複数の作業を全自動化してくれるRPAのように、システムの力に任せられる部分はどんどん任せてしまう仕組み作りこそが「守りのDX」の基本となります 。 それによって削減され、新しく生み出された貴重な時間やリソースを、今度は顧客満足度を向上させるための「攻めのDX」へと投資していくのです 。 この攻めと守りのスパイラルを継続的に回し続けることによって、単なる一過性の効率化で終わらない、終わりのない真のイノベーションが組織の中に定着していくようになります 。
サーバー運用の注意点
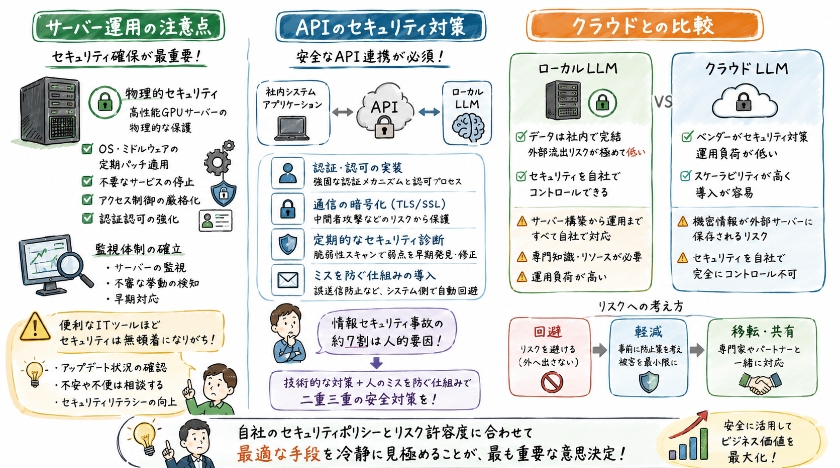
ローカルLLMを導入する上で、サーバー運用の注意点はセキュリティ確保の要となります。
高性能GPUを搭載したサーバーの物理的なセキュリティはもちろんのこと、OSやミドルウェアの定期的なパッチ適用、不要なサービスの停止など、基本的なセキュリティ対策を徹底する必要があります。
また、ローカルLLMへのアクセス制御を厳格に行い、認証認可のシステムを堅固に構築することが重要です。
不正アクセスやデータ漏洩のリスクを最小限に抑えるため、サーバーの監視体制を確立し、不審な挙動を早期に検知・対応できる運用体制の確立が、社内での安全なローカルLLMの活用を保証します。 便利なITツールを使う上で、どうしてもセキュリティ対策は無頓着になりがちですが、万が一事故が発生すれば社会的信頼は一気に落ちてしまいます 。 だからこそ、一般的に優れたITツールが常にアップデートを繰り返しているように 、使用するシステムが何年も放置された状態にならないよう、日頃からアップデートの頻度などを注意深く調べておく姿勢が大切です 。 何か不便や不安が生じたときには、自分で抱え込まずに周囲の得意な人やサポートに相談できるような、個人のセキュリティリテラシーを高める取り組みも同時に進めていきましょう 。
APIのセキュリティ対策
ローカルLLMを社内システムやアプリケーションと連携させる際には、APIのセキュリティ対策が不可欠です。
APIの設計段階から認証メカニズムや認可プロセスを組み込み、機密情報への不正アクセスを防ぐ強固な対策を講じる必要があります。
また、API通信にはTLS/SSLによる暗号化を常に適用し、中間者攻撃などのリスクから保護します。
定期的なAPIのセキュリティ診断や脆弱性スキャンを実施し、潜在的な弱点を早期に発見・修正することで、ローカルLLMを活用した業務処理の安全性を継続的に確保し、社内データの保護に努めることが重要です。 どんなに優れたシステムを構築しても、人的な誤操作や設定ミスを完全にゼロにすることは難しく、情報セキュリティ事故の7割はこうした人的要因から発生しているという現実もあります 。 メールの誤送信防止機能のように、システム側の機能であらかじめミスを指摘したり自動的に回避したりできるような仕組みをAPI連携の段階から組み込んでおくことは、トラブルを防ぐ非常に有効な手段となります 。 組織内の重要なデータを守るためには、技術的な暗号化だけでなく、こうした人間のミスを未然に防ぐ二重三重の壁を作ることが、真の安心安全へと繋がっていくのです 。
クラウドとの比較
ローカルLLMのセキュリティを語る上で、クラウドLLMサービスとの比較は重要な視点です。
クラウドサービスはベンダーがセキュリティ対策を行うため、自社での運用負荷は低い一方で、機密情報が外部のサーバーに保存されるという根本的なリスクが伴います。
これに対し、ローカルLLMは社内ネットワーク内でデータ処理が完結するため、機密情報の外部流出リスクを極めて低く抑えることが可能です。
ただし、ローカルLLMの場合、サーバーの構築から運用、セキュリティ対策まですべて自社で行う必要があり、専門的な知識とリソースが求められます。 私自身、かつてシステムを開発する側と使う側の両方の現場にどっぷりと浸かってきましたが 、すべてを独力でやろうとすると、どこかで大きな壁にぶつかって行き詰まってしまうものです 。 企業が直面するリスクへの対策には、リスクそのものを避けるために外へ持ち出さないようにする「回避」や、事前に防止策を考えて被害を最小限に抑える「軽減」といった様々な考え方があります 。 すべてを自社で抱え込もうとせず、専門知識を持つパートナーの手を借りたり、自社のセキュリティポリシーとリスク許容度に合わせて最適な手段を冷静に見極めたりすることこそが、「超DX仕事術」において最も重要な意思決定となるのです 。
RAGの基本概念
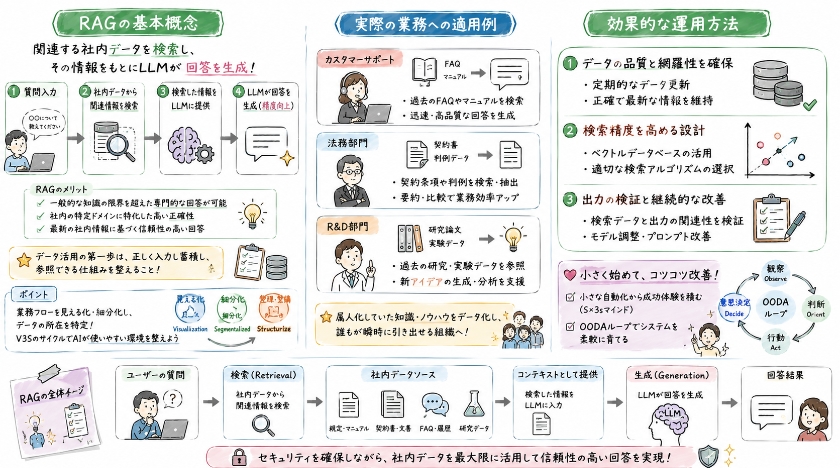
RAG(Retrieval-Augmented Generation)は、ローカルLLMの性能を飛躍的に向上させるための技術であり、特に社内データの活用においてその真価を発揮します。 この技術は、ローカルLLMが回答を生成する前に、関連性の高い社内データソースから情報を検索し、その情報を入力としてモデルに与えることで、生成される情報の精度と正確性を向上させます。 これにより、一般的なモデルが持つ知識の限界を超え、企業の特定ドメインにおける専門的な知識に基づいた、より信頼性の高い回答を生成することが実現されます。
自社のデータを効果的に活用することで、ローカルLLMの実用性を大きく高め、業務への適用範囲を広げることが可能です。 「超DX仕事術」でもお伝えしている通り、データを活用するためには、まずデータを正しく入力し、蓄積すること、そしてそれらを参照できる仕組みが不可欠です。 どれほど優れたAIであっても、元となるデータがバラバラに散らばっていては、その知能を100パーセント発揮させることはできません。 まずは現状の業務フローを見える化し、細分化し、どこにどのようなデータが眠っているのかを特定するV3Sのサイクルを意識して、AIがアクセスしやすい環境を整えていきましょう。
実際の業務への適用例
RAGの技術は、実際の業務において多岐にわたる活用が可能です。 例えば、カスタマーサポートでは、顧客からの問い合わせに対して、過去のFAQや製品マニュアルといった社内データから関連情報を検索し、ローカルLLMが正確性の高い回答を生成することで、迅速かつ高品質な対応を実現できます。 また、法務部門では、契約書や判例データをRAGで活用し、特定の条項に関する情報を抽出し、要約を生成することで、業務効率の向上を図ることが可能です。
R&D部門においても、過去の研究論文や実験データを参照しながら、新しいアイデアの生成や分析を支援し、企業のイノベーションを加速させることが期待されます。 このように、RAGはローカルLLMの活用範囲を広げ、社内の様々な業務プロセスを最適化するための強力なツールとなります。 これは個人の仕事を誰でも引き継げるようにして大躍進を遂げた、酒蔵の旭酒造の事例とも本質は同じです。 これまで一部のベテラン社員の頭の中にしか入っていなかった経験やノウハウをデータ化し、RAGを通じて誰もが瞬時に引き出せるようにすることは、組織全体の生産性を革命レベルにまで引き上げる原動力となります。
効果的な運用方法
RAGを効果的に運用するためには、いくつかの重要な方法と検討事項があります。 まず、参照する社内データの品質と網羅性が極めて重要です。 データが古かったり、不正確であったりすると、モデルの生成する回答の品質も低下するため、定期的なデータの更新と整理が不可欠です。 次に、検索の精度を高めるための設計も重要です。
ベクトルデータベースの活用や、適切な検索アルゴリズムの選択により、ローカルLLMに提供されるコンテキストの品質が向上します。 さらに、モデルの出力と検索されたデータの関連性を検証し、必要に応じてモデルの調整やプロンプト設計の改善を行うことで、より実用的で正確性の高いRAGシステムを構築できます。 最初から完璧なシステムを目指して莫大なコストと時間をかけるのではなく、まずは小さな業務の自動化からコツコツと成功体験を積み重ねていくS×3sマインドが大切です。 状況を素早く観察し、判断し、行動へと移すOODAループを回しながら、現場のフィードバックに合わせてシステムを柔軟に育てていくことこそが、安全で効果的な運用を実現する一番の近道となります。
自社におけるシステム構築の方法
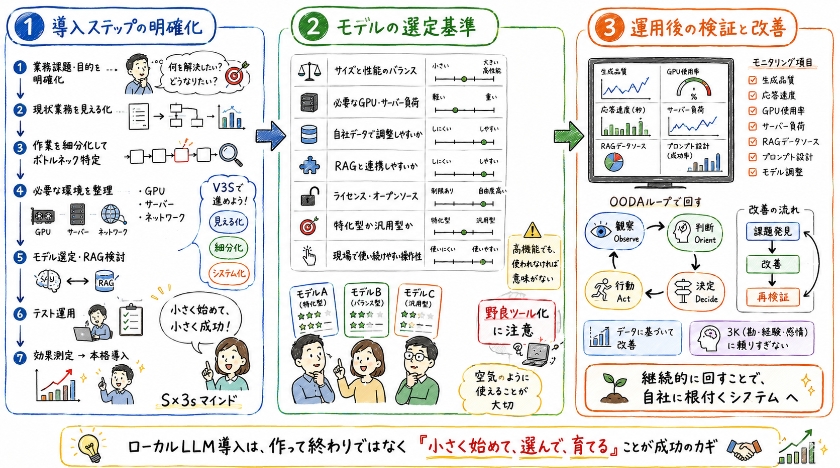
導入ステップの明確化
自社でローカルLLMシステムを構築するには、明確な導入ステップを踏むことが成功の鍵となります。
最初のステップは、具体的な業務課題と目的を特定し、ローカルLLMがどの用途で活用されるべきかを定義することです。
次に、必要なGPUスペックやサーバーなどのハードウェア環境、ネットワーク環境の整備を含め、技術的な要件を詳細に検討します。
その後、オープンソースのモデルの中から自社の目的に最も適したものを選定し、必要に応じて自社データでの調整やRAGのような技術の導入を計画します。
最後に、構築されたシステムのテスト運用と、効果測定のための検証プロセスを設計し、社内への本格導入へと進みます。 「超DX仕事術」でも解説している通り、ITツールの導入自体が目的となっていては目に見える効果はなかなか得られません 。 大切なのは、最初から完璧な巨大システムを作ろうと身構えるのではなく、未完成のテスト版からでも「小さく始めて、小さく成功し、小さく積み重ねる」というS×3sマインドを持つことです 。 まずは現状の業務を紙に書き出して見える化し(Visualization)、作業を細分化して(Segmentalized)ボトルネックを特定した上で、最適なシステムを組み込む(System)というV3Sのフレームワークを意識して、1ステップずつ着実に進めていきましょう 。
モデルの選定基準
ローカルLLMを自社システムに導入する際のモデル選定は、その後の運用と性能を大きく左右する重要な要素です。
選定基準としては、まずモデルのサイズと性能のバランスを検討する必要があります。
大規模なモデルほど生成されるデータの品質は高い傾向にありますが、その分必要なGPUスペックやサーバーリソースも大きくなります。
次に、自社のデータで調整が可能か、あるいはRAGのような技術との連携がスムーズに行えるかも重要なポイントです。
また、ライセンスやオープンソースであるかどうかも企業のポリシーに応じて検討が必要です。 特定の業務に特化するのか、汎用的な用途に利用するのかによっても適切なモデルは異なるため、これらの要素を総合的に比較し、自社のニーズに最も合致するモデルを選定することが重要です。 私自身、これまで数え切れないほどのITツールに触れてきたオタクですが 、ツール選びで最も重要なのは「メンバー全員に空気のように使い続けられること」だと考えています 。 いくら高機能なモデルであっても、操作が難解で現場が使わなくなってしまえば、それらは企業のセキュリティリスクやコストを垂れ流すだけの「野良ツール」へと成り下がってしまいます 。 社内のITリテラシーや業務スタイルをしっかりと考慮した上で、自社にとって最適なモデルを選択しましょう 。
運用後の検証と改善
ローカルLLMシステムの導入はゴールではなく、継続的な運用と改善が重要です。
初期導入後、モデルの性能と精度が業務要件を満たしているかを定期的に検証する必要があります。
生成されるデータの品質、応答速度、リソース使用状況などを詳細にモニタリングし、課題を特定します。
例えば、特定のプロンプトで不正確な情報が生成される場合は、モデルの調整やプロンプト設計の見直し、RAGのデータソースの改善を検討します。
また、サーバーの負荷状況やGPU使用率を分析し、必要に応じて環境の最適化やスペックの増強を行うことで、システム全体の効率と実用性を向上させます。 こうした改善のプロセスには、従来のじっくり計画を立てる手法よりも、目まぐるしく変化する戦場で適切に判断するために生まれた「OODA(ウーダ)ループ」という思考方法が極めて有効です 。 最新の利用状況をよく観察し(Observe)、自社の業務に合わせた情勢を判断し(Orient)、改善策を決定して(Decide)、実際に動かしてみる(Act) 。 人間が陥りがちな3K(勘・経験・感情)の主観に頼ることなく、可視化された正確なデータに基づいてこのループを柔軟に回し続けることこそが、システムを自社に深く根付かせ、長期的な生産性向上を実現するための唯一の方法なのです 。
ローカルLLM:社内データ活用とセキュリティ確保のための環境構築に関しての「よくある質問」
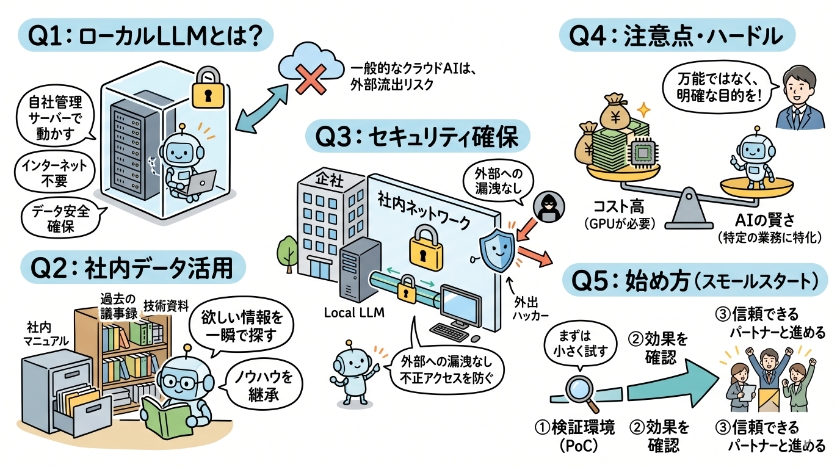
Q1: ローカルLLMとは何ですか?一般的なAI(ChatGPTなど)と何が違うのでしょうか?
ローカルLLMとは、インターネット上にある大手のクラウドサービスを利用するのではなく、自社が管理するサーバーやパソコン(ローカル環境)の中に構築して動かす人工知能(生成AI)のことです。
一般的なChatGPTなどのクラウド型AIは、手軽で高性能ですが、入力したデータがAIの学習に使われたり、外部に漏洩したりするリスクがゼロではありません。一方、ローカルLLMは「自社専用の閉じられた環境」で動くため、最高レベルのデータ安全性を確保できるのが最大の決定的な違いです。
Q2: 社内データとローカルLLMを組み合わせると、どのようなことができるようになりますか?
自社がこれまでに蓄積してきた膨大な「社外秘のデータ」を、安全かつ最大限に有効活用できるようになります。
具体的には、以下のような業務の劇的な効率化(DX)が実現します。
社内マニュアルや過去の膨大な議事録から、欲しい情報を一瞬で探し出すAIアシスタントの構築
技術資料や製品仕様書を学習させ、ベテラン社員のノウハウを若手に継承する自動応対システム
顧客の個人情報や機密情報を含む、社内稟議書や報告書の自動作成・校正
外部のAIには絶対に読み込ませられないコアな経営資源(データ)を、安全に知的な資産へと変えることができます。
Q3: セキュリティを確保するために、具体的にどのような環境構築を行うのですか?
もっとも重要なのは、「企業の社内ネットワーク(イントラネット)から一歩も外にデータを出さない仕組み」を作ることです。
具体的には、自社で保有する物理サーバー、または完全に隔離されたクラウド上の専用スペース(VPCなど)にAIを配置します。これにより、AIとのやり取りがすべて社内で完結するため、情報漏洩やサイバー攻撃、外部からの不正アクセスのリスクを極めて低く抑えることが可能になります。まさに「自社専用の金庫の中にAIを飼う」ようなイメージです。
Q4: 導入にあたって、初心者が気をつけるべき注意点やハードルはありますか?
主に「コスト」と「AIの賢さ(性能)」のバランスに注意が必要です。
ローカルLLMを自社でスムーズに動かすには、GPUと呼ばれる画像処理等に使う高性能で高価な半導体(パーツ)が必要になり、初期投資や維持費が高くなる傾向があります。また、世界中のお金を集めて作られたChatGPTなどの巨大なクラウドAIに比べると、ローカル環境で動く小規模なAIは、「一般的な文章作成や雑談の能力」では一歩劣る場合があります。
そのため、何でもできる万能なAIを目指すのではなく、「自社の特定の業務に特化して賢くする」という明確な目的意識を持つことが成功の秘訣です。
Q5: 初めてローカルLLMの環境構築にチャレンジする場合、何から始めればよいですか?
まずは、小さく始めて効果を検証する「スモールスタート(PoC)」から始めるのが鉄則です。
いきなり高額なサーバーを購入するのではなく、まずはセキュリティが担保されたクラウドの検証環境などを利用し、「本当に自社のデータを使って業務が効率化するか」を一部の部署だけで実験してみましょう。オープンソースとして無料で公開されている優れたAIモデル(LlamaやMistralなど)もたくさんありますので、信頼できるDXパートナー(コンサルタントやシステム開発会社)と相談しながら、自社の目的と予算に合った最適なモデルを選ぶことからスタートしてみてください。
DXやITの課題解決をサポートします! 以下の無料相談フォームから、疑問や課題をお聞かせください。40万点以上のITツールから、貴社にピッタリの解決策を見つけ出します。
このブログが少しでも御社の改善につながれば幸いです。
もしお役に立ちそうでしたら下のボタンをクリックしていただけると、 とても嬉しく今後の活力源となります。 今後とも応援よろしくお願いいたします!
IT・通信業ランキング | にほんブログ村 |
もしよろしければ、メルマガ登録していただければ幸いです。
【メルマガ登録特典】AI戦略で10年以上勝ち続ける実践バイブル『AI競争勝者の法則』をプレゼント!
 今すぐプレゼントを受け取る
今すぐプレゼントを受け取る