「AIの導入は進んでいるはずなのに、コストばかりかさんで利益につながっていない…」─そんな焦りや悩みを抱えていませんか?
2026年現在、AIやデータ活用は「とりあえず試してみる」という実験のフェーズに完全に終わりを告げました。今や、企業の収益性や競争力を直接左右する「実用」の段階へと突入しています。 特に大規模言語モデル(LLM)の進化は目覚ましく、単なる文章作成のサポート役から、業務プロセスを自律的にこなす「AIエージェント」へと変貌を遂げました。
しかし、便利になった一方で、その裏側には「複雑なコスト構造」と「技術的負債」という恐ろしい落とし穴が潜んでいます。目先の新技術にとらわれて場当たり的な導入を続ければ、気づいた時には取り返しのつかない運用コストを背負い込むことになりかねません。
では、どうすればリスクを回避し、AIを真のビジネスの武器にできるのでしょうか?
この記事では、なんと340%という驚異的なROI(投資利益率)を達成した実例を交えながら、最新のデータ基盤の作り方からAIエージェントの全社展開、そして無駄なコストを削ぎ落とす「AI FinOps」までを徹底解説します。
技術の進化にただ振り回されるのではなく、2026年の厳しいビジネス環境を勝ち抜き、持続的な成長を手にするための「明日から使える具体的なロードマップ」をお渡しします。
簡単に説明する動画を作成しました!
目次
意思決定の土台を築く:モダン・データ基盤の選択と進化
現在においてデータ基盤は単なるITインフラではなくAIというエンジンの出力を最大化するための高品質な燃料供給システムといえます。
私がこれまでDXコンサルタントとして多くの現場を見てきた経験から言えるのはここでのアーキテクチャ選択ミスは将来の拡張性を奪うだけでなくモデルの精度低下や予期せぬ運用コスト増大といった致命的な欠陥を招くということです 。
データが構造化されているかリアルタイムでAIエージェントがアクセス可能かという選択がビジネスの柔軟性を左右する戦略的資産となるのです。
超DX仕事術でお伝えしたV3Sというフレームワークを使ってまずは現状のデータの流れを可視化し細分化して特定してみると自社のデータ基盤のボトルネックが見えてくるはずです 。
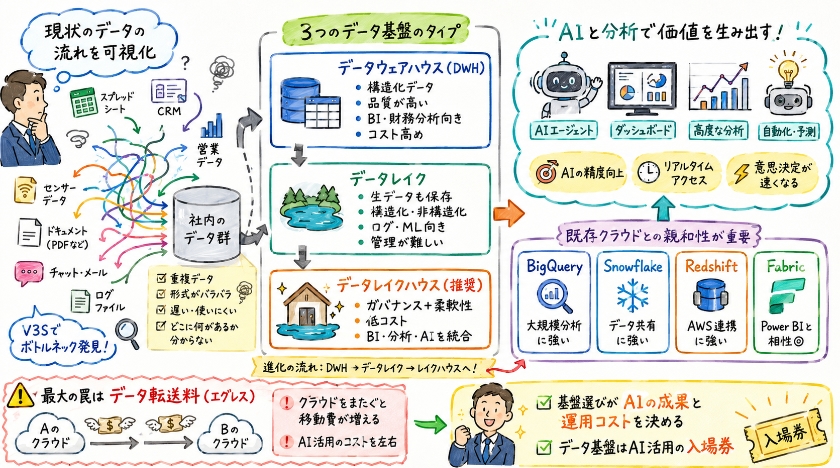
データウェアハウス、データレイク、そしてレイクハウスの理解
現在のデータ基盤は従来のデータウェアハウスDWHとデータレイクの長所を統合したデータレイクハウスへと収束しています。
それぞれの特徴を整理するとデータウェアハウスはきれいに整理された構造化データを扱いSchema-on-writeという形式で高い品質と一貫性を保つためBIや財務分析や定型レポート作成に向いていますがクエリ準備済み環境への支払いが必要なためコスト効率は低く高くなりがちです。
一方でデータレイクは構造化と非構造化が混合した生データも含めて保存できるSchema-on-readの安価なオブジェクトストレージを利用するシステムでログ分析やメディアや機械学習ML用の大規模生データに向いていますが管理が難しいという側面があります。
そしてこれらを統合したデータレイクハウスはデータウェアハウスのガバナンスとデータレイクの柔軟性を低コストで両立し重複を排除して単一環境で全工程を完結させるためBIから高度な分析やAI機械学習の統合ワークロードにまで対応します。
特徴 | データウェアハウス (DWH) | データレイク | データレイクハウス |
|---|---|---|---|
特徴(スキーマ・形式) | 構造化データ(Schema-on-write)。高い品質と一貫性。 | 生データ(構造化・非構造化混合)。Schema-on-read。 | DWHのガバナンスと、レイクの柔軟性を低コストで両立。 |
コスト効率 | 高い(クエリ準備済み環境への支払いが必要)。 | 低い(安価なオブジェクトストレージを利用)。 | 非常に高い(重複を排除し、単一環境で全工程を完結)。 |
主な用途 | BI、財務分析、定型レポート。 | ログ分析、メディア、ML用の大規模生データ。 | BI、高度な分析、AI/機械学習の統合ワークロード。 |
ここでの核となる洞察はレイクハウスが主流となっている最大の理由がパフォーマンスとコストの劇的な均衡にあるということです。
Databricks SQLに代表されるこのモデルは安価なオブジェクトストレージ上のデータに対してDWH同等のガバナンスとクエリ速度を提供します。
データを複製したり移動することなくBIから機械学習まで実行できるため運用コストが激減しデータの一貫性が飛躍的に向上するのです。
「ビッグスリー」とエンタープライズ向けソリューションの比較
クラウドデータ基盤の選択は既存のインフラ環境であるAWSやAzureやGCPとの親和性Affinityが長期的な運用コストに直結します。
Googleが提供するBigQueryはサーバーレスな超大規模分析とマルチクラウド戦略をとる企業に最適です。
BigQuery Omniによるクロスプラットフォーム分析やSQLベースの組み込みML機能などのメリットがありますがクエリ設計の不備が予期せぬコスト高を招くリスクがある点には注意が必要です。
Snowflakeはマルチクラウド環境でのシームレスなデータ共有と多様な言語による開発に適しています。
Snowparkと呼ばれるPythonやJavaに対応した高度なアプリ開発やCortexによる管理型AI機能が使えるメリットの反面クレジットベースの価格体系が予算管理を複雑にするというデメリットを持っています。
Amazonが提供するRedshiftはAWSエコシステムに深く依存しリアルタイム性が求められる環境にベストな選択肢です。
Zero ETL機能による他のサービスAuroraやDynamoDB等からの即時データ同期が強みですがAWS全般の深い知識を前提とした複雑な最適化設定が必要になるという難点があります。
Microsoftが提供するFabricはAzure環境でPower BIを主軸に全社的なデータ民主化を推進する企業に向いています。
OneLakeによる統合ストレージを持ちSaaS型でデータエンジニアリングからBIまでひとつのサービスで完結するメリットがありますがAzureエコシステム外との連携に制約が生じるベンダーロックインの懸念が残ります。
ここでのSo What?レイヤーとしてお伝えしたい基盤選択における最大の罠はデータの転送料と呼ばれるエグレスの存在です。
私が過去にクライアント先で痛感したことですが既存インフラと異なるクラウドにAI用データを配置すると毎月のデータ移動費用がライセンス料を凌駕することになります。
データ基盤の整備はAI活用の入場券に過ぎません。
その先にはAI導入に伴うコストの氷山というシビアな現実が待ち構えていることを忘れないでください。
AI導入の現実:コストの氷山とスケールへの挑戦
多くの企業がAIを導入するときに見落としがちなのはライセンスの料金は氷山の一角に過ぎないという厳しい事実です。
私がお手伝いしてきた現場でもお試しとなるパイロットプロジェクトを成功させてもいざ全社展開へ移行しようとすると多くの企業が効果検証の繰り返しというパイロット地獄に陥ってしまいます。
そして結果的にシステムを拡大していくスケールアップの大きな障壁に直面しているのを何度も目にしてきました。
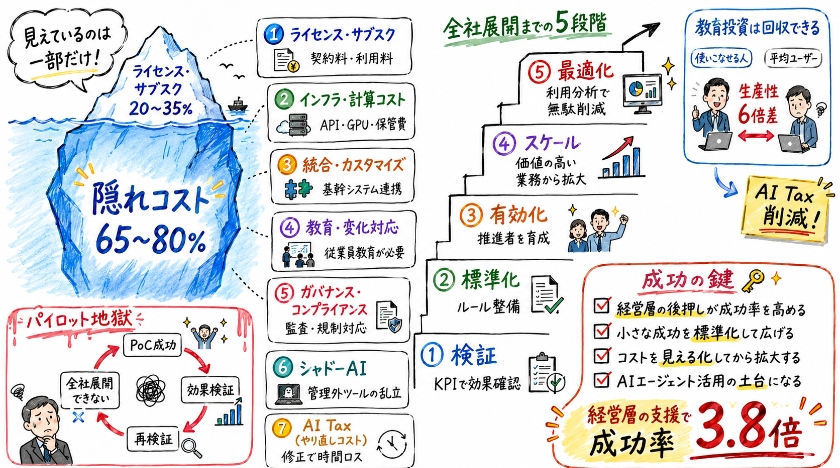
AI総所有コストTCOの構造:隠れたコストを可視化する
ソースのデータによればAIのライセンス費用は総コストのわずか20パーセントから35パーセントにすぎません。
残りの65パーセントから80パーセントは次の7つのコストのカテゴリーとしてまさに水面下に隠れているのです。
1つ目はライセンスや毎月支払うサブスクリプションの費用でありCopilotやChatGPT Enterpriseといったサービスを直接利用するための料金でこれが全体の25パーセント程度を占めます。
2つ目はインフラや計算にかかるコストで別のシステムと連携するAPIの呼び出しや高度な画像処理を行うGPUの割り当てや独自のデータを読み込ませる仕組みを作るためのデータ保管費用などが含まれます。
3つ目は統合とカスタマイズの費用で顧客管理システムや企業の根幹となるシステムと接続するためのものであり1つの主要なツールを統合するのに約2200万円以上かかる例も珍しくありません。
4つ目はトレーニングと変化への対応管理であり従業員1人あたり数十万円規模の教育費が必要となり継続的にスキルをアップデートしていく必要があります。
5つ目はガバナンスとコンプライアンスで監査やルールの適用や規制への対応が含まれもしEUのAI規制法に違反した場合には最大で約56億円もの罰金リスクが伴うことになります。
6つ目はシャドーAIのコストで会社の管理外で個人が勝手に契約しているものを指しIT担当の役員が把握している数の3倍から5倍のAIツールが実際には使われていると言われています。
超DX仕事術でも野良ツールなどシャドーITの危険性について触れましたが管理されていないツールがはびこることはコスト面でもセキュリティ面でも非常に危険です。
そして7つ目がAITaxと呼ばれる低習熟度によるやり直しコストであり不適切な出力を修正する作業のことでAIで節約された時間の37パーセントがこのやり直しで失われているのです。
分析の視点として特に注目していただきたいのはAIを使いこなせる人と平均的なユーザーの間にある6倍の生産性のギャップです。
教育への投資は単なる出費ではなくこのやり直しコストであるAITaxを削減し投資に対する利益を劇的に向上させるための戦略的なレバーとなります。
パイロットから全社展開へ:成功のための5段階フレームワーク
AIのプロジェクトは8割以上が失敗に終わるというデータがある中で成功を収めている企業は次に挙げるフェーズを必ず守って進めています。
まず検証のフェーズではAIができるかどうかではなく具体的なビジネスの指標が改善されるかどうかをしっかりと証明します。
超DX仕事術でお伝えしたV3Sというフレームワークを使って現状を可視化し細分化して特定してみるとどこを改善すべきかが見えてくるはずです。
次に標準化のフェーズでは一時的な成功をシステムとして定着させデータの流れや管理のルールをきれいに整備していきます。
続いて有効化のフェーズに入り推進者となるネットワークを社内に構築して部門ごとに生じるスキルの差を埋めていきます。
そしてスケールのフェーズで価値の高い業務のフローから同心円を描くように少しずつ導入の範囲を拡大していきます。
最後に最適化のフェーズで利用状況を細かく分析し不要な支出を削って投資に対する利益を最大化するのです。
成功の鍵となるのは経営層がプロジェクトを強力に後押しする体制でありこれがあるだけで成功率は3.8倍も高まります。
経営層が自らAIを活用して評価の制度にAIによるインパクトを組み込むことが組織全体にある時間差のラグを解消する唯一の道といえます。
この組織的な準備こそが次世代のAIエージェントを活用していくための扉を開く鍵となるのです。
2026年の主役:AIエージェントの解剖学と実活用
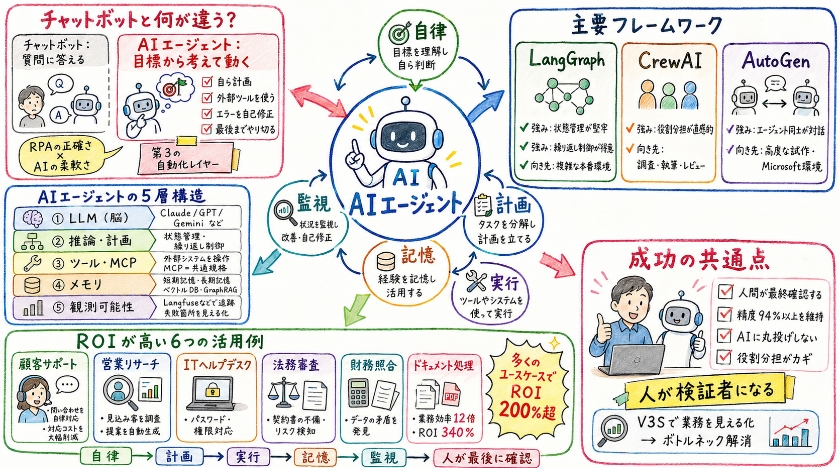
AIエージェントは従来のチャットボットとは一線を画す自律的な意思決定者です。
目標を与えれば自ら計画を立てて外部ツールを駆使しエラーを自己修正しながら完結させます。
これは第3の自動化レイヤーと呼ばれ決まった作業を正確にこなすRPAと状況に合わせて考えるAIの柔軟性を融合させたビジネスインパクトをもたらします。
私が超DX仕事術でお伝えしたV3Sのフレームワークで業務を見える化してみるとこのAIエージェントがいかに業務のボトルネックを解消してくれるかがよくわかるはずです。
AIエージェントの5層アーキテクチャと主要フレームワーク
2026年の標準的なエージェント構成は以下の5つの層で成り立っています。
第1層はLLMと呼ばれる推論エンジンでエージェントの脳にあたります。
コスト効率重視のClaude 4.6やSonnetや汎用性の高いGPT-4.5や画像なども扱えるGemini 2.0が標準となっています。
第2層は計画を担う推論エンジンで状態の管理と繰り返しの作業を制御する神経系の役割を果たします。
第3層は行動を起こすツールやMCPで外部のシステムを操作する手のようなものです。
MCPというModel Context Protocolの規格はツールを一度書けばどのシステムでも使える共通の規格としての戦略的な価値を持ちます。
第4層は記憶を司るメモリで短期間のセッションの記憶と長期間のベクトルDBの記憶を保持しGraphRAGなど過去のデータを引き出す仕組みを含んでいます。
第5層はモニタリングを行う観測可能性でLangfuseなどを用いて行動を追跡しどのステップで失敗したかを見える化します。
これらの仕組みを動かすための主要なフレームワークもいくつか存在します。
LangGraphは状態管理が堅牢で繰り返しの制御が容易なためエンタープライズ向けの複雑な本番環境に適しています。
CrewAIは複数のエージェントへの役割分担が直感的に行えるため調査や執筆やレビューといったリサーチ業務に向いています。
AutoGenはエージェント間の自然な言葉による対話型の調整ができるためMicrosoftの環境内での高度な試作機の開発などに使われます。
フレームワーク | 強み | 適したユースケース |
|---|---|---|
LangGraph | 状態管理が堅牢。サイクル(繰り返し)の制御が容易。 | エンタープライズ向けの複雑な本番環境。 |
CrewAI | 複数のエージェントへの「役割分担」が直感的。 | 調査、執筆、レビューといったリサーチ業務。 |
AutoGen | エージェント間の自然言語による対話型調整。 | Microsoftエコシステム内での高度なプロトタイプ。 |
ROIを最大化するエンタープライズ・ユースケース
以下の6つの主要なユースケースでは投資に対する利益が200パーセント以上になることが実証されています。
顧客サポートでは問い合わせの60パーセントから80パーセントを自律的に解決し1件あたりのコストが0.41ドルから0.07ドルへ83パーセントも削減される例もあります。
営業リサーチでは数千件の見込み客を調査してそれぞれに合わせた提案を自動で生成してくれます。
ITヘルプデスクではパスワードのリセットや権限の診断などを自動化します。
法務審査では契約書の不備や法律上のリスクを自動で検知することが可能です。
財務の照合では企業内のデータ間にある矛盾や不整合を特定します。
ドキュメント処理については欧州の保険会社の事例でAIエージェントの導入により業務効率が12倍も向上し投資に対する利益が340パーセントを達成したという結果が出ています。
分析の視点として成功の共通点は人間による最終検証を取り入れていることです。
AIにすべてを任せるのではなく人間が検証者として関わることで精度を94パーセント以上に保ちつつリスクを最小限に抑えています。
超DX仕事術でも触れたようにシステムと人間の役割分担をうまく行うことが今後のビジネスを変革していく鍵となるのです。
持続可能なAI戦略:コスト最適化とパートナー選定の極意
AIへの支出が指数関数的に増大する2026年において、財務管理であるFinOpsや管理体制であるガバナンスの欠如は、プロジェクトが途中で止まってしまう最大の要因となります。
価値1ドルあたりのコストを最小化するような、しっかりとした財務的なルールが必要です。
私自身、コンサルタントとして多くの企業のIT導入を支援してきましたが、費用対効果を見誤って途中で予算が尽きてしまうケースを何度も目にしてきました。
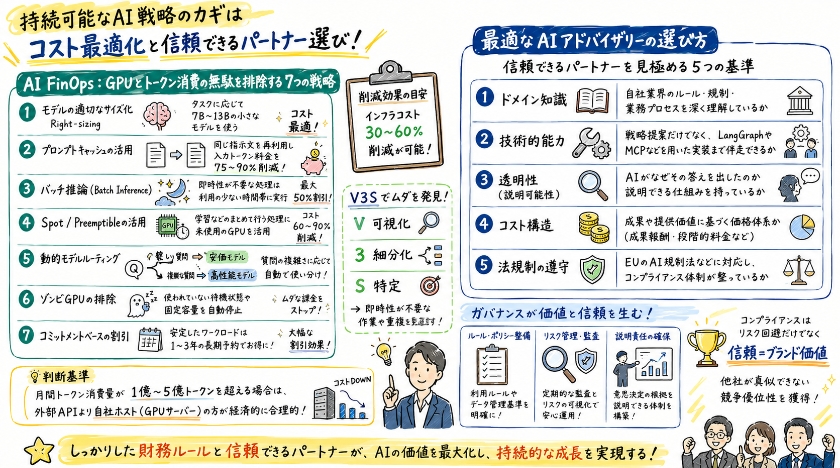
AI FinOps:GPUとトークン消費の無駄を排除する7つの戦略
インフラにかかるコストを30パーセントから60パーセント削減するため、組織は直ちに以下の戦略を確認用のリストにすべきです。
まず、モデルの適切なサイズ化であるRight-sizingです。
高度な推論が不要な簡単なタスクには、7Bから13B程度の安価で小規模なモデルを割り当てます。
次に、プロンプトキャッシュの活用です。
これは同じ指示文を再利用することで、入力にかかるトークン料金を75パーセントから90パーセント削減することが可能です。
そして、バッチ推論と呼ばれるBatch Inferenceです。
すぐに結果が必要ない処理は利用者が少ない時間帯に実行し、50パーセントの割引を受けます。
超DX仕事術でお伝えしたV3Sのフレームワークで業務を見直してみると、即時性が必要ないムダな作業が意外と多いことに気づくはずです。
また、SpotやPreemptibleといった一時的に安く使えるサーバーインスタンスを利用します。
モデルの学習などのまとめて行う処理に、まだ使われていない画像処理装置であるGPUを活用し、コストを60パーセントから90パーセント削減します。
動的モデルルーティングでは、質問の複雑さに応じて、安価なモデルと高性能なモデルを自動で使い分けます。
さらに、ゾンビGPUの排除も重要です。
誰も使っていないのに課金が続いてしまう待機状態のシステムや、固定された容量を自動的に停止させます。
最後に、コミットメントベースの割引です。
日常的に発生する安定した作業に対しては、1年から3年の長期間の利用予約を行います。
判断基準の公式として、月間のトークン消費量が1億から5億トークンを超えるような場合は、外部のAPIを利用するよりも、自社でGPUサーバーを管理する自社ホストの方が、経済的な合理性が高まります。
最適なAIアドバイザリーの選び方とガバナンス
AIの導入を支援するアドバイザリー市場は、2033年までに年平均成長率35.8パーセントで2570億ドル規模に達すると予測されています。
ITツールオタクである私も、日々新しいサービスが登場するスピードには驚かされるばかりですが、有象無象の業者が乱立する中で適切なパートナーを選ぶ基準は以下の通りとなります。
一つ目はドメイン知識で、金融や製造といった自社業界特有のルールや規制に精通しているかどうかが問われます。
二つ目は技術的能力で、単なる戦略の提案だけでなく、LangGraphやMCPといった技術を用いた実際の実装まで一緒に伴走できるかが重要です。
三つ目は透明性で、AIモデルがなぜその答えを出したのかという説明可能性を担保し、中身がわからないブラックボックス化を避けているかを確認します。
四つ目はコスト構造で、提供した価値や成果に基づく価格体系を持っているかを見極めます。
そして法規制の遵守についてですが、EUのAI規制法などのルールを守ることは、単なるリスク回避ではありません。
信頼という名のブランド価値を築き、他社が真似できない競争の優位性を獲得するための手段なのです。
明日から取るべき最初のステップ
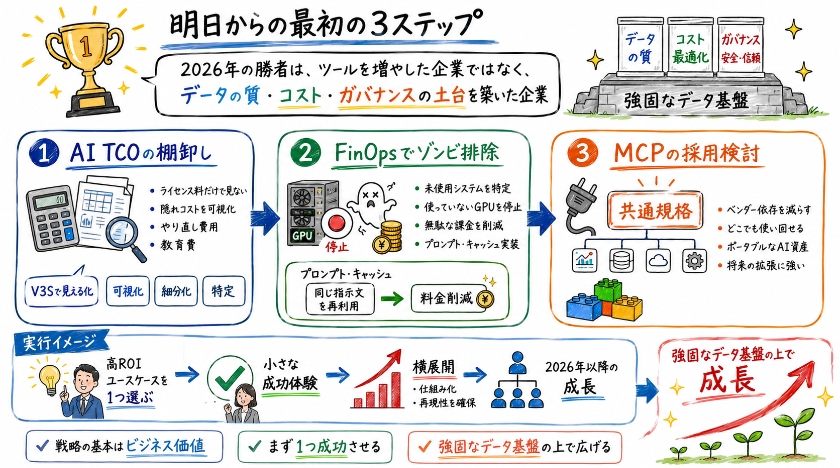
2026年、AIの真の勝者は、最も多くのツールを導入した企業ではありません。
データの質やコスト、そしてガバナンスという土台を最も堅牢に築いた企業こそが勝者になります。
これは私がDXコンサルタントとして多くの現場を支援する中で、深く痛感してきた現実でもあります。
読者のみなさんが明日から着手すべきアクションは、以下の3点です。
AI TCOの棚卸し
まずはAIの総所有コストである、AI TCOの棚卸しです。
超DX仕事術の基本であるV3Sのステップに沿って、まずは現状を見える化することが大切です。
ライセンス料以外の隠れたコスト、つまり不適切な出力を修正するやり直し費用や従業員の教育費が、予算の何パーセントを占めているかを可視化しましょう。
FinOpsによるゾンビ排除
次に、無駄な財務支出を管理するFinOpsによるゾンビ排除です。
契約したまま未使用になっているシステムやGPUインスタンスを特定し、無駄な課金を徹底的に排除してください。
それと同時に、同じ指示文を再利用することで料金を大きく削減できるプロンプト・キャッシュを今すぐ実装しましょう。
MCPの採用検討
最後は、共通規格であるMCPの採用検討です。
特定の開発ベンダーだけに依存しない、どこでも柔軟に使い回せるポータブルなAIツール資産の構築を開始することです。
テクノロジーの進化はこれからも加速し続けますが、戦略の基本は常にビジネス価値にあります。
まずは一つの投資対効果が高いユースケースで小さな成功体験を積み重ね、それを強固なデータ基盤の上で横展開していくことが、2026年以降の成長を確かなものにするでしょう。
DXやITの課題解決をサポートします! 以下の無料相談フォームから、疑問や課題をお聞かせください。40万点以上のITツールから、貴社にピッタリの解決策を見つけ出します。
このブログが少しでも御社の改善につながれば幸いです。
もしお役に立ちそうでしたら下のボタンをクリックしていただけると、 とても嬉しく今後の活力源となります。 今後とも応援よろしくお願いいたします!
IT・通信業ランキング | にほんブログ村 |
もしよろしければ、メルマガ登録していただければ幸いです。
【メルマガ登録特典】AI戦略で10年以上勝ち続ける実践バイブル『AI競争勝者の法則』をプレゼント!
 今すぐプレゼントを受け取る
今すぐプレゼントを受け取る